 Solo para Entendidos
Solo para Entendidos
¿Y si pudieras filtrar miles de patrones de velas en los mercados y quedarte solo con los pocos que realmente anticipan movimientos?
Eso es exactamente lo que logra el trabajo “Entropy-Assisted Quality Pattern Identification in Finance” — y los resultados son sorprendentes.
El Problema: Patrones por Todas Partes, Señales Claras por Ninguna
En el análisis técnico, las estrategias basadas en patrones de precio abundan. Pero cuando se trabaja con series temporales de alta frecuencia (por ejemplo, barras de 30 minutos de un activo como el oro), la cantidad de ruido y la cantidad de patrones “parecidos” pero con resultados opuestos hace que sea casi imposible confiar en una señal sin sobreajustar el modelo.
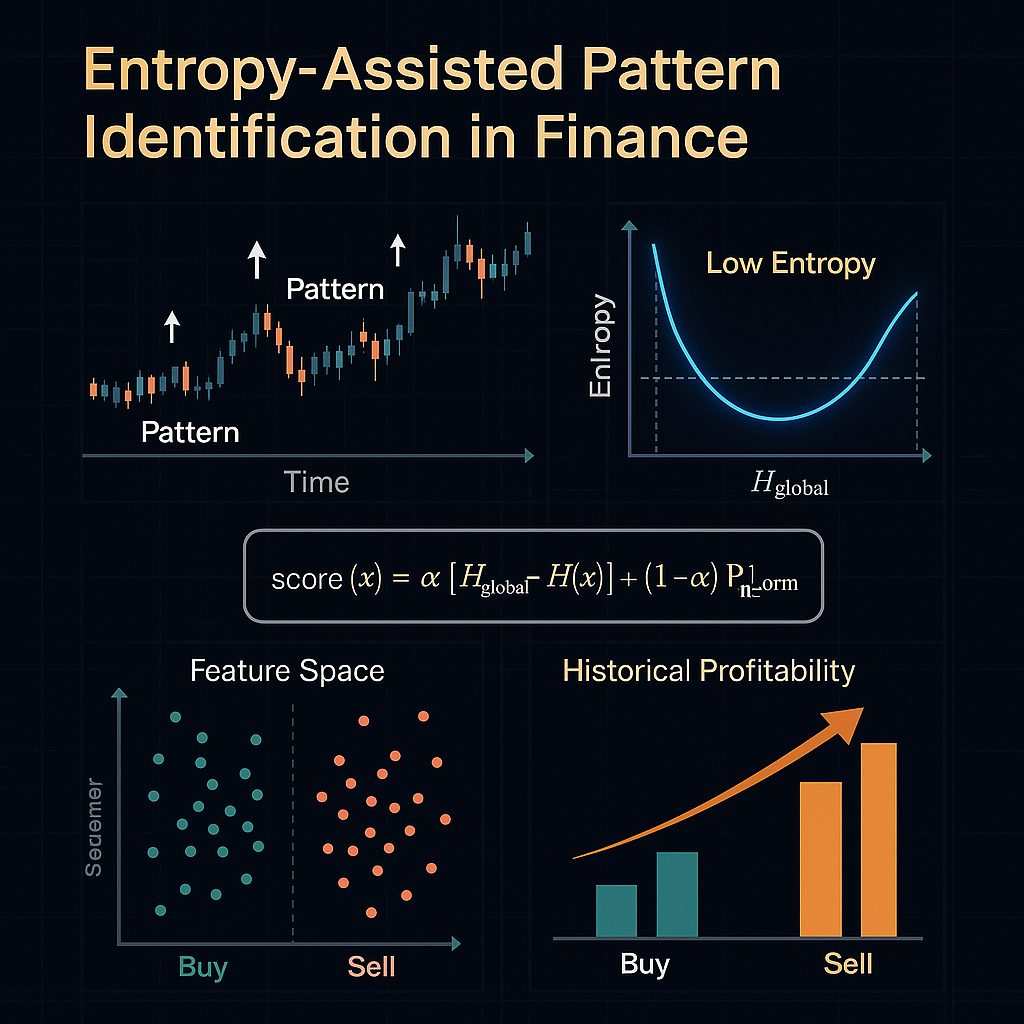
El aporte central de este paper es aplicar la teoría de la información a la búsqueda de patrones: un patrón es valioso solo si, en su “vecindario” de patrones similares, casi siempre produce el mismo resultado. Esta “pureza” se mide usando la entropía de Shannon, una métrica que indica cuánta incertidumbre (o sorpresa) hay en los resultados de ese patrón.
El Motor de Selección: Entropía + Rentabilidad Histórica
El algoritmo propuesto busca patrones de secuencias OHLC (Open, High, Low, Close) usando ventanas de 8 barras de 30 minutos (un espacio de 32 dimensiones si se usan 4 diferencias por barra). Para cada patrón candidato, se calcula:
- Entropía Local:
Se mide la entropía de los resultados obtenidos por todos los patrones cercanos en el espacio de características.- Si la mayoría de los patrones similares llevan al mismo resultado (compra o venta), la entropía es baja y el patrón es “puro”.
- Si los resultados son mezclados o impredecibles, la entropía es alta y el patrón es descartable.
- Rentabilidad Histórica Normalizada:
Se estima cuánto habría ganado (o perdido) ese patrón en la historia, ajustando la métrica para comparar entre patrones. - Puntaje Combinado:
Finalmente, ambos componentes se combinan en un “score”: CopyEditscore(x) = α · [ H_global – H(x) ] + (1 – α) · PnL_norm(x)Dondeαes un peso (en el paper, 0.8),H_globales la entropía total,H(x)es la entropía local, yPnL_norm(x)es la ganancia normalizada.
Limpieza y Selección de la Biblioteca de Patrones
El proceso de selección no termina ahí:
Después de ordenar los patrones por su puntaje, se elimina la superposición. Si hay dos patrones (uno de compra y otro de venta) demasiado similares entre sí, solo sobrevive el de mayor score.
Así se evita el problema típico de tener “patrones doble agente” que pueden sugerir compras y ventas en situaciones casi idénticas.
Resultado final:
- El set original tenía casi 2.000 patrones, llenos de solapamientos.
- Tras filtrar, quedan aproximadamente 1.150 patrones realmente diferenciados y relevantes, con una mejor separación entre señales de compra y de venta.
¿Funciona en la Práctica? Prueba Real en Oro (2017–2024)
Para probar la robustez del método, los autores lo aplicaron al futuro de oro (Gold-USD), entrenando el modelo con datos de 2017 a 2023 y probando en el desafiante 2024 (el año más volátil de la muestra).
¿El resultado?
Usando parámetros diversos, la estrategia logra retornos anualizados del 30% al 60% en datos nunca vistos, sin sobreajuste y con estabilidad ante cambios en los parámetros.
¿Por Qué No Simplemente Clusterizar con K-Means o GMM?
El paper también compara este método con algoritmos clásicos de agrupamiento (clustering).
Si bien métodos como K-Means pueden funcionar en 2D, en espacios de alta dimensión (como este) tienden a agrupar de forma desbalanceada y a crear bibliotecas con muchos más patrones de un lado que del otro, generando señales ambiguas o inútiles.
La clave del método basado en entropía es que no busca “lindos” clusters geométricos, sino patrones que realmente aporten información predictiva.
Principales Aportes y Lo que Significa para el Trader
- Entropía como filtro de pureza: Permite separar patrones determinísticos de los aleatorios, previniendo el sobreajuste.
- Score dual (Entropía + PnL): Combina la confianza estadística con la utilidad económica real.
- Bibliotecas no solapadas: Evita patrones “doble agente” que generan señales ambiguas.
- Set de señales balanceado: Mantiene una cantidad similar de patrones de compra y venta, crucial para estrategias sistemáticas.
- Resultados reales: La estrategia logra entre 30% y 60% anualizado en el año más difícil de la muestra, lo que sugiere ventaja genuina.
Próximos pasos y Futuro
El equipo propone explorar entropía de Tsallis (más robusta a distribuciones con colas pesadas, típicas en finanzas) y aplicar técnicas de “pivot moves” para recorrer el espacio de patrones de forma más eficiente.
Conclusión
Este trabajo muestra cómo la teoría de la información puede llevar la identificación de patrones de trading a un nuevo nivel, permitiendo separar la señal del ruido con criterios cuantitativos y aplicables a la vida real.
Si tu estrategia actual depende de clustering o del “ojo entrenado”, es hora de probar cómo la entropía puede limpiar tu biblioteca de señales y mejorar tus resultados.
Referencia: ArXiv:2503.06251v1 [q-fin.TR] 8 Mar 202
