Solo para Entendidos
Solo para Entendidos
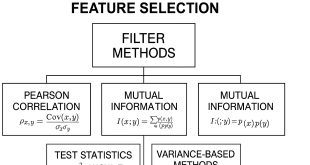
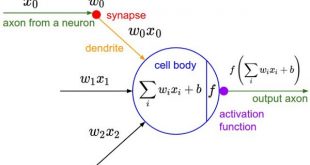
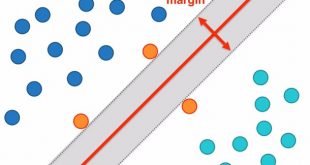
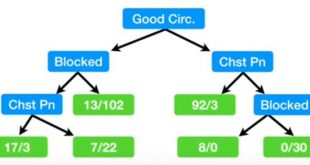
1. Introducción y Justificación La selección de características es una etapa fundamental en el preprocesamiento de datos para machine learning, especialmente en contextos de alta dimensionalidad como el financiero. Los métodos de filtro constituyen una clase de técnicas diseñadas para seleccionar un subconjunto informativo de variables (features) evaluando únicamente propiedades …
Read More »Métodos de Filtro para Selección de Características en Machine Learning